Gireg Lanoë, Acsystème
[01:22] Hello everyone, I’m Gireg Lanoë. I’m a Design Engineer at Acsystème. I’m going to introduce you to the topic starting with a presentation of the problem, the context, the study which was carried out with Matlab Simulink, the tools that we deployed to help PSA and finally the conclusion.
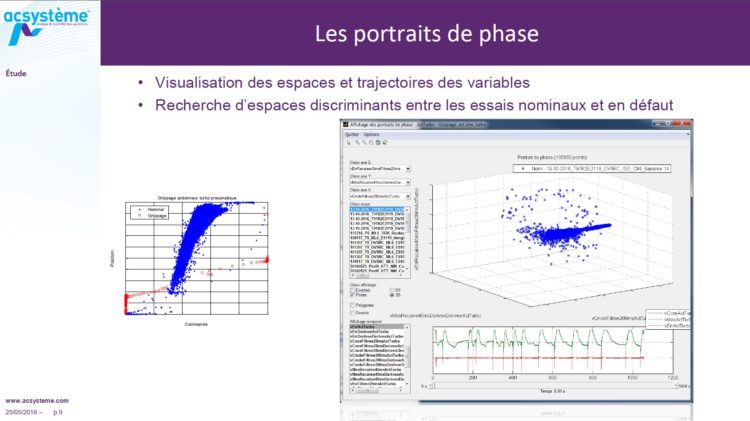
The first part: the context, it’s diagnostics! What is diagnostics? On an engine, there are instructions which are sent by the driver, meaning that he accelerates, brakes and changes gear. Diagnostics: the engine receives messages from the sensors. Diagnostics involve analysing any potential inconsistencies between what has been sent, what the engine is asked to do and what the engine actually does. If there is a discrepancy, depending on the severity of the fault, there will be different types of warning lights that can light up on the dashboard and which will also be visible at the dealership.
The challenge for engine diagnostics is to reduce the number of after-sales service visits, particularly during the warranty period. There is a clear advantage for the manufacturer, because as soon as we can identify the fault, we will be able to repair the correct component and therefore carry out a rapid intervention. Also customer satisfaction: if the customer needs to make several return trips to the garage, satisfaction is likely to drop. Therefore, the challenge is to improve the quality of engine diagnostics, in particular by identifying the source more accurately, so as to reduce intervention time and achieve a good detection compromise. In other words, a detection method will always be a compromise between non-detection and false anomaly. The risk of non-detection is that the day on which the component breaks is not detected: “We’re stopped at the side of the road”. And the false anomaly, on the other hand, will create what is known as the “Christmas tree effect”. In other words, the warning light on the vehicle’s dashboard will come on unexpectedly when in fact there is no fault.